DrM: Mastering Visual Reinforcement Learning through Dormant Ratio Minimization
Abstract
Visual reinforcement learning (RL) has shown promise in continuous control tasks. Despite its progress, current algorithms are still unsatisfactory in virtually every aspect of the performance such as sample efficiency, asymptotic performance, and their robustness to the choice of random seeds. In this paper, we identify a major shortcoming in existing visual RL methods that is the agents often exhibit sustained inactivity during early training, thereby limiting their ability to explore effectively. Expanding upon this crucial observation, we additionally unveil a significant correlation between the agents' inclination towards motorically inactive exploration and the absence of neuronal activity within their policy networks. To quantify this inactivity, we adopt dormant ratio as a metric to measure inactivity in the RL agent's network. Empirically, we also recognize that the dormant ratio can act as a standalone indicator of an agent's activity level, regardless of the received reward signals. Leveraging the aforementioned insights, we introduce DrM , a method that uses three core mechanisms to guide agents' exploration-exploitation trade-offs by actively minimizing the dormant ratio. Experiments demonstrate that DrM achieves significant improvements in sample efficiency and asymptotic performance with no broken seeds (76 seeds in total) across three continuous control benchmark environments, including DeepMind Control Suite, MetaWorld, and Adroit. Most importantly, DrM is the first model-free algorithm that consistently solves tasks in both the Dog and Manipulator domains from the DeepMind Control Suite as well as three dexterous hand manipulation tasks without demonstrations in Adroit, all based on pixel observations.
Highlights
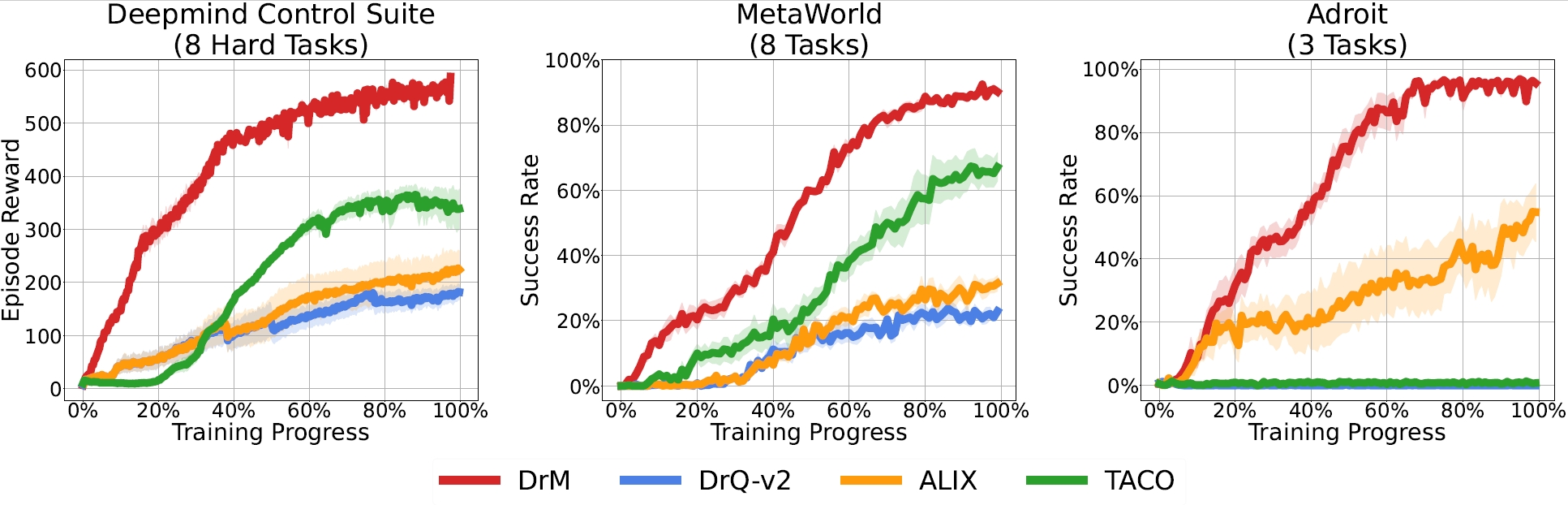
We evaluate DrM on three benchmarks for both locomotion and robotic manipulation: DeepMind Control Suite, Meta-World, and Adroit. These environments feature rich visual elements like textures and shading, necessitate fine-grained control due to complex geometry, and introduce additional challenges such as sparse rewards and high-dimensional action spaces that previous visual RL algorithms like DrQv2 have been unable to solve.
DeepMind Control Suite
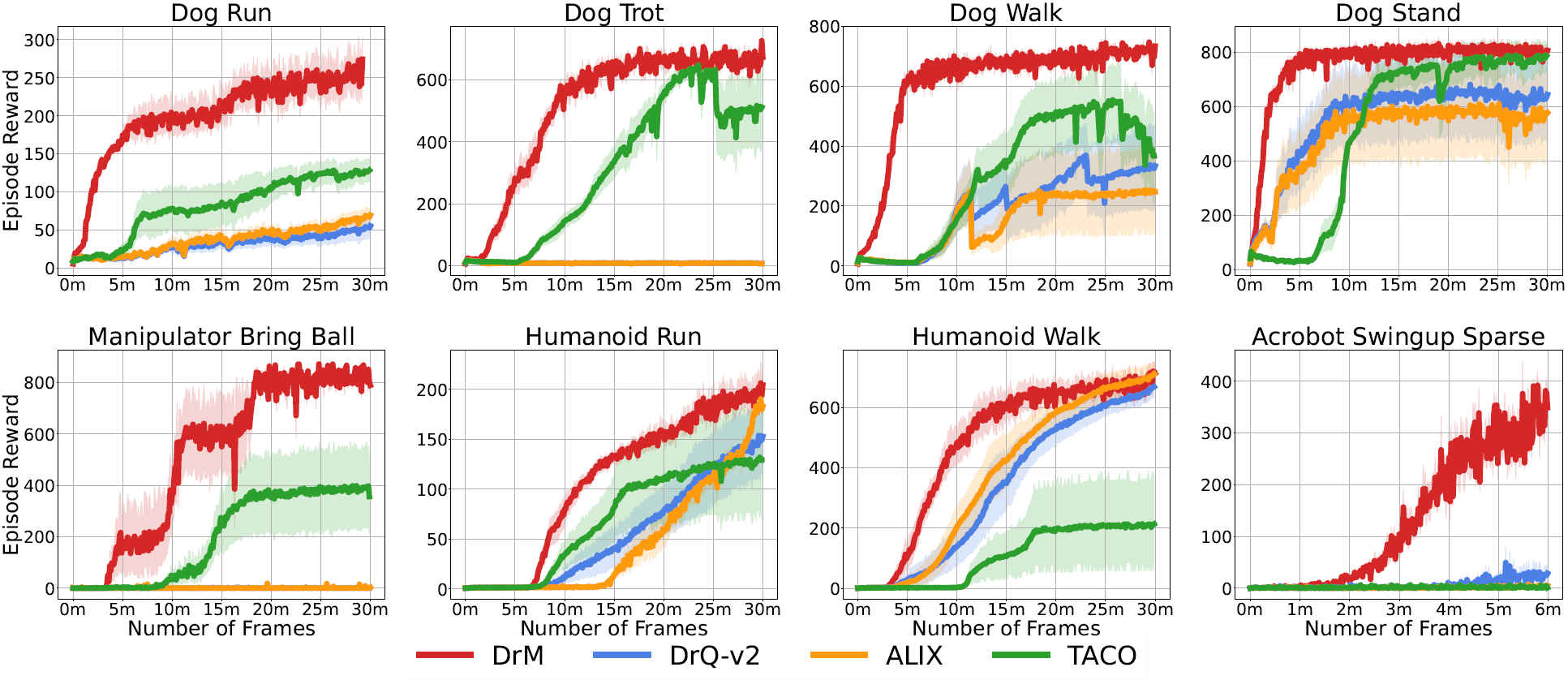
For Deepmind Control Suite, we evaluate DrM on eight hardest tasks from the Humanoid, Dog, and Manipulator domain, as well as Acrobot Swingup Sparse.
Meta-World
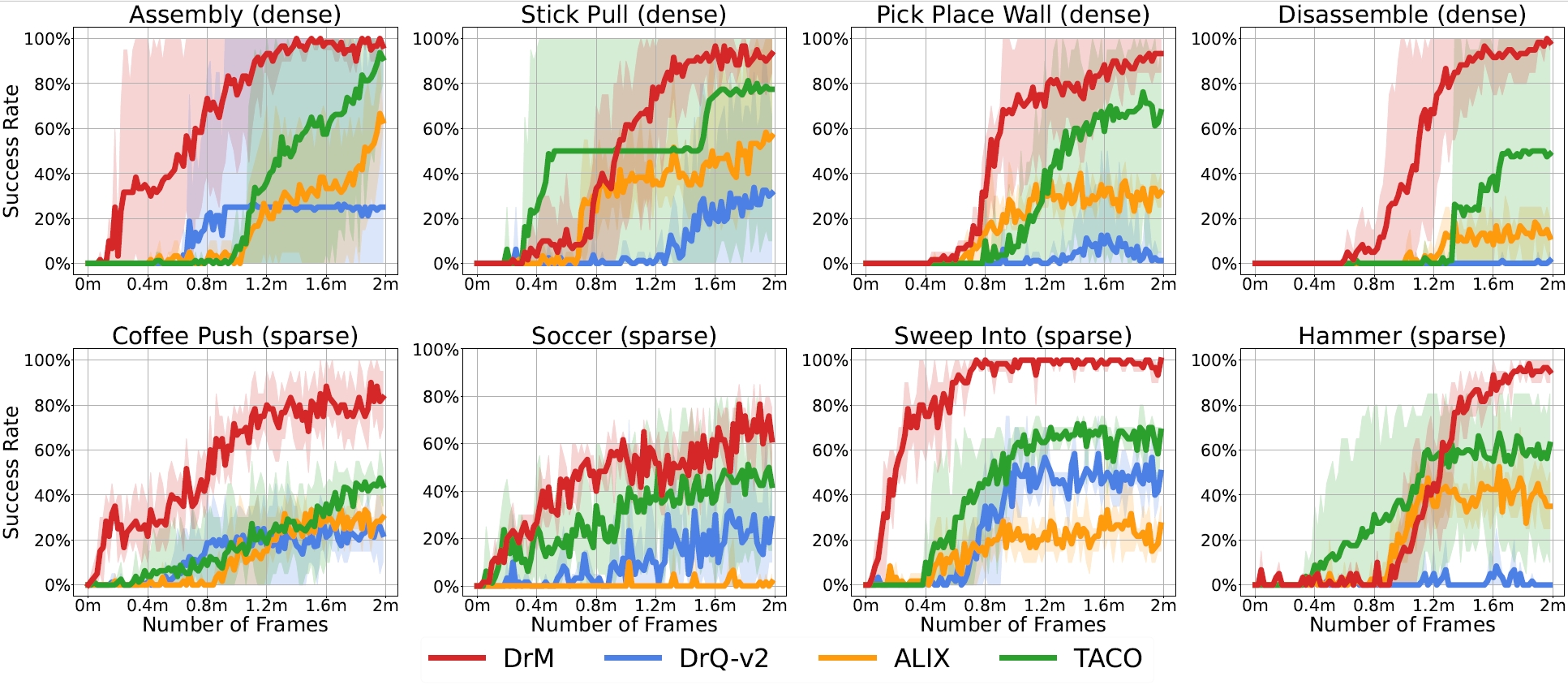
In Meta-World, we evaluate DrM and baselines on eight challenging tasks including 4 very hard tasks with dense rewards following prior works and 4 medium tasks with sparse success signals.






Adroit
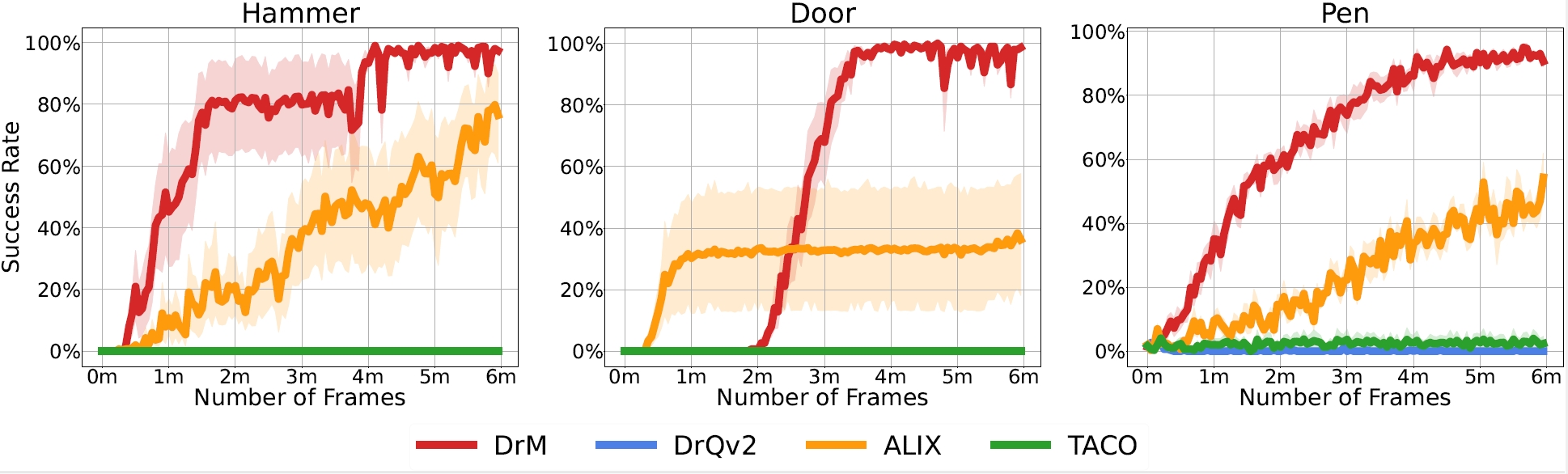
We also evaluate DrM on the Adroit domain, focusing on three dexterous hand manipulation tasks: Hammer, Door, and Pen. Notably, DrM is the first documented model-free visual RL algorithm capable of reliably solving tasks in the Adroit domain without expert demonstrations.
Dormant Ratio and Behavioral Variety
We notice that a sharp decline in the dormant ratio of an agent's policy network serves as an intrinsic indicator of the agent executing meaningful actions for exploration. Namely, when the dormant ratio is high, the agent becomes immobilized and struggles to make meaningful movements. However, as this ratio reduces, there's a noticeable progression in the agent's movement levels.
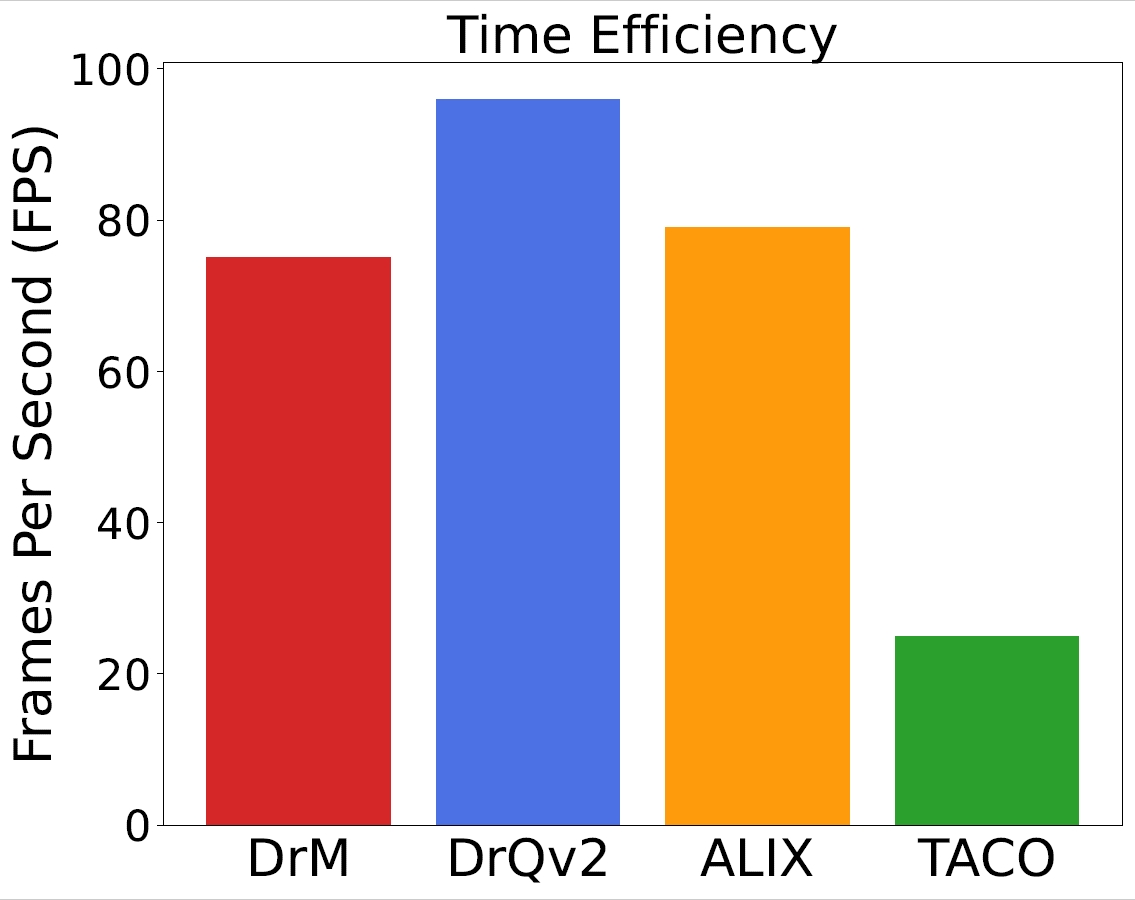
Time Efficiency
To assess the algorithms' speed, we measure their frames per second (FPS) on the same task, Dog Walk, using an identical Nvidia RTX A5000 GPU. While achieving significant sample efficiency and asymptotic performance, DrM only slightly compromises wall-clock time compared to DrQ-v2. Compared with two other baselines, DrM is roughly as time-efficient as ALIX and about three times faster than TACO.